Predicting Housing Prices with Natural Language Processing NLP and Tidymodels
In this tutorial, we will be predicting housing prices based on their descriptions. We will be using natural language processing, NLP, to build a machine learning model. We will be using bag of words with column vectors of ones and zeros. If you want to reproduce the analysis or check out the code, then you can find it on my GitHub.
A lot of data is generated each day and a lot of it is text data. Today, I wanted to analyze some real estate descriptions that I previously scraped from the web. I used a random forest regression model with the typical predictors, the number of baths, beds, square feet, etc. It was fun and I wanted to try something different. Therefore I decided to analyze the job descriptions with natural language processing, bag of words, and a lasso regression model.
What we will be covering:
- Exploring the data
- Data preprocessing
- Preparing the data for 10-fold cross-validation
- Lasso machine learning model fitting
- Model evaluation
- Conclusion
Data Exploration of Housing Prices
First, we will be reading in the data and then cleaning it up a bit. We will be removing outliers and potentially false data points.
library(tidyverse)
library(tidymodels)
library(textrecipes)
library(parallel)
housing <- readr::read_csv("data/df.csv")
# removes houses with missing (unrealistic) year_built values
housing <- housing[housing$year_built < 2030, ]
# remove houses that cost more than 3 million
housing <- housing[housing$price < 3000000, ]
# remove square feet that are too low
housing <- housing[housing$sqft > 100, ]
housing <- housing %>%
dplyr::select(price, description, website) %>%
dplyr::filter(website == "buying") %>%
na.omit() %>%
dplyr::select(-website) %>%
dplyr::mutate(description = stringr::str_remove_all(description,
"[0-9]+"))
dplyr::glimpse(housing)
## Rows: 2,244
## Columns: 2
## $ price <dbl> 1188000, 1288000, 2399000, 1315000, 2850000, 2699000, 259…
## $ description <chr> "prestigious concrete air-conditioned boutique building i…
In the end we have 2,244 rows and 2 columns. One column with the price, our response variable, and the other one is the housing descriptions. We also removed all numbers in the description as we only want to focus on the words.
ggplot(housing, aes(x = sqrt(price))) + geom_histogram(binwidth = 40) + theme_minimal()

I transformed the response variable to make it look a bit more normally distributed.
Data Preprocessing For NLP and Tidymodels textrecipes
For the preprocessing steps, we will be using the textrecipes package from the tidymodels. We will be transforming the response variable, tokenize the description stemming the words to their affixes and suffixes, removing all the stop words, only keeping the top 2500 words, and then translating the output into ones and zeros. I am keeping a lot of predictors because I will be using the Lasso model which will take care of the variance and shrink a lot of the predictors to zero. If I were to use another model, I would go with around 500 words.
The steps that we described above are coded below:
remove_words <- c(
"https", "bldg", "covid", "sqft", "bdrms",
"only.read", "included.read", "moreview", "&",
"baths", "bdrm", "bath", "feet", "square", "amp",
"sq.ft", "beds", "you’ll", "uniqueaccommodations.com",
"rentitfurnished.com", "it’s", "http", "below:https",
"change.a", "january", "february", "march", "april",
"may", "june", "july", "september", "october", "listing.to",
"november", "december", "note:all", "property.to", "link:http",
"www.uniqueaccomm", "www.uniqueaccomm", "change.to", "furnishedsq",
"craigslist.rental", "craigslist.professional", "ft.yaletown",
"ft.downtown"
)
recipe_nlp <- recipe(price ~., data = housing) %>%
recipes::step_sqrt(price) %>%
textrecipes::step_tokenize(description) %>%
textrecipes::step_stem(description) %>%
textrecipes::step_stopwords(description) %>%
textrecipes::step_stopwords(description,
custom_stopword_source = remove_words) %>%
textrecipes::step_tokenfilter(description, max_tokens = 2500) %>%
textrecipes::step_tf(description, weight_scheme = "binary") %>%
recipes::step_mutate_at(dplyr::starts_with("tf_"), fn = as.integer)
We also included some stop words that we thought are not contributing to a better predictability of the model.
Cross-Validation for NLP with Tidymodels rsample
Next, we want to do 10-fold cross-validation for the best lambda and to get a sense of what the test set error will be. We do that with the rsample package from the tidymodels framework.
set.seed(1)
split <- rsample::initial_split(housing)
train <- rsample::training(split)
test <- rsample::testing(split)
folds <- rsample::vfold_cv(train, v = 10)
tune_spec <- parsnip::linear_reg(penalty = tune::tune(), mixture = 1) %>%
parsnip::set_engine("glmnet")
lambda_grid <- dials::grid_regular(dials::penalty(range = c(-3, 3)), levels = 100)
nlp_wflow <-
workflows::workflow() %>%
workflows::add_recipe(recipe_nlp) %>%
workflows::add_model(tune_spec)
all_cores <- parallel::detectCores()
library(doFuture)
doFuture::registerDoFuture()
cl <- makeCluster(all_cores)
plan(cluster, workers = cl)
I the code above, we are splitting the data set into training and testing/validation data sets. Then we are creating the 10 folds from the training data set. If you want to learn more about cross-validation, you can check out this post about cross-validation in machine learning and the bias-variance trade-off and also this one where it discusses how to do cross-validation the wrong way and right way.
We then specify the model where we want to tune the penalty. For that, we will be trying out different values with tune::grid_values() from the tidymodels framework. The mixture is set to one because we are using the lasso model. We then add the recipe we created earlier and the model specification to our workflow and then set up the model fitting in parallel.
NLP Model Fitting and NLP Model Evaluation
res <-
nlp_wflow %>%
tune::tune_grid(
resamples = folds,
grid = lambda_grid,
metrics = yardstick::metric_set(yardstick::mae,
yardstick::rsq)
)
autoplot(res)
We are using our previously created workflow and the 10 folds to evaluate which lambda results in the best mean absolute error. I like the easy interpretation of the mean absolute error. Alternatively, we could have used rmse which penalizes more for outliers and is not as interpretable as mae.
When we plot the mae and r-squared we get this:

The mean absolute error is…
tune::collect_metrics(res) %>% dplyr::filter(.metric == "mae") %>% dplyr::arrange() %>% .[["mean"]] %>% .[[1]] ## [1] 149.0941
… 149.
Now, we are selecting the best lambda and then fitting the lasso model on all the training data.
best_mae <- tune::select_best(res, "mae") final_lasso <- tune::finalize_workflow( nlp_wflow, best_mae ) final_lasso ## ══ Workflow ════════════════════════════════════════════════════════════════════ ## Preprocessor: Recipe ## Model: linear_reg() ## ## ── Preprocessor ──────────────────────────────────────────────────────────────── ## 8 Recipe Steps ## ## ● step_sqrt() ## ● step_tokenize() ## ● step_stem() ## ● step_stopwords() ## ● step_stopwords() ## ● step_tokenfilter() ## ● step_tf() ## ● step_mutate_at() ## ## ── Model ─────────────────────────────────────────────────────────────────────── ## Linear Regression Model Specification (regression) ## ## Main Arguments: ## penalty = 2.8480358684358 ## mixture = 1 ## ## Computational engine: glmnet
housing_final <- tune::last_fit(
final_lasso,
split,
metrics = yardstick::metric_set(yardstick::mae,
yardstick::rsq)
)
tune::collect_metrics(housing_final)
## # A tibble: 2 x 4
## .metric .estimator .estimate .config
## <chr> <chr> <dbl> <chr>
## 1 mae standard 146. Preprocessor1_Model1
## 2 rsq standard 0.528 Preprocessor1_Model1
We have a mean absolute error of 146 and an r-squared of around 146.
Visualizing NLP Important Words
Next, we will have a look at what predictors are most important in our NLP Lasso model.
housing_vip <- housing_final %>%
pull(.workflow) %>%
.[[1]] %>%
workflows::pull_workflow_fit() %>%
vip::vi()
housing_vip %>%
dplyr::mutate(Variable = stringr::str_remove(Variable, "tf_description_")) %>%
dplyr::group_by(Sign) %>%
dplyr::slice_max(abs(Importance), n = 20) %>%
ungroup() %>%
mutate(
Variable = fct_reorder(Variable, Importance)
) %>%
ggplot(aes(Importance, Variable, fill = Sign)) +
geom_col() +
facet_wrap(~Sign, scales = "free") +
labs(y = NULL) +
theme_minimal() +
theme(legend.position = "none")
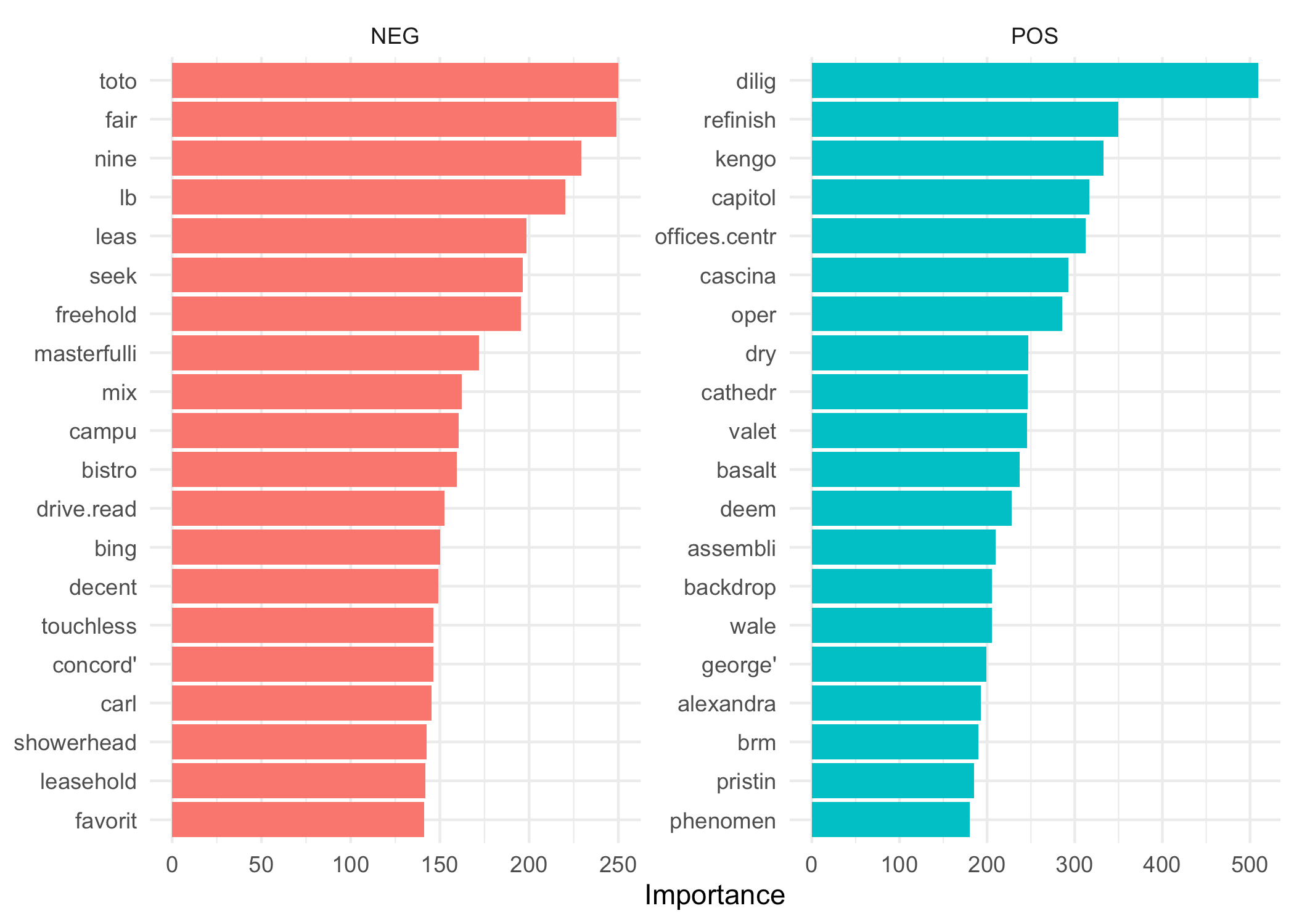
The words you can see above are the top 20 words that are affecting the price of a real estate properly most positively and negatively.
Next, we will have a look at our predictions.
tune::collect_predictions(housing_final) %>%
ggplot(aes(x = .pred, y = price)) +
geom_point(alpha = 0.4) +
geom_abline(slope = 1, linetype = "dotted",
col = "red", size = 1) +
theme_minimal()

We can see that for lower property prices, our model is overestimating the prices more and for higher property prices the model is predicting them more to be less than the actual value.
When we look at the mean absolute error, then we can see that our model is off $332,929 on average. For a three million house that would be 10% off which is not bad but for properties priced at $500,000 that’s pretty bad. Overall, our model is decent at best, however, given that we only used words and no bigrams or anything else it is not too bad. Maybe some more accuracy can be achieved by some more feature engineering.
tune::collect_predictions(housing_final) %>% dplyr::mutate(mae = abs(.pred^2 - price^2)) %>% .[["mae"]] %>% mean() ## [1] 332929.3
Let me know if you have any questions in the comments below.
Comments (3)
Awesome work. How do you think house features can be added so both NLP and numerical features can be used for the model?
Hello! This seems really cool and I would love to try it out! Do you have your data set posted somewhere?
Sorry, I had that data set on an old computer I am not able to access anymore 🙁