A Practical Data Wrangling Example of purrr’s imap Function
Lately, I have been looking at purrr‘s imap function and was wondering in which cases it is useful. I have always wanted to use it but never found the right problem to try it out until last week at work.
Today I will be sharing a short example about purrr‘s pmap function to provide some inspiration.
Let’s start by providing the toy data set.
set.seed(123)
library(tidyverse)
replicate(paste0(sample(c(0, 1), size = 5, replace = TRUE), collapse = ""), n = 1000) %>%
{ data.frame(source_flags = .) } %>%
dplyr::mutate(source_flags = as.character(source_flags)) -> toy_df
# source_flags
# <chr>
# 01011
# 01110
# 10110
# 10001
# 11111
# 11100
# 11110
# 01000
# 00000
# 00001
Our data frame consists of a source_flags column that contains a character strings of ones and zeros. The ones and zeros indicate whether a person has data from the following data sources or not:
- Tax
- Immigration
- Healthcare
- Credit Card
- Education
The task is to identify how many people have a certain combination of these data sources.
First, Some Data Manipulation
toy_df %>%
dplyr::mutate(source_flags = stringr::str_split(source_flags, pattern = "")) %>%
{ purrr::map(dplyr::pull(., var = "source_flags"), ~paste0(., collapse = " ")) } %>%
{ dplyr::mutate(toy_df, source_flags = purrr::flatten_chr(.)) } %>%
tidyr::separate(col = "source_flags", into = c("tax", "immigration", "healthcare",
"credit", "education")) -> intermediate_df
head(intermediate_df)
# tax immigration healthcare credit education
# 1 0 1 0 1 1
# 2 0 1 1 1 0
# 3 1 0 1 1 0
# 4 1 0 0 0 1
# 5 1 1 1 1 1
# 6 1 1 1 0 0
Code explanation:
- First, I split the character string into individual parts
- What I get back is a list. Therefore, I am using
purrr‘smapfunction, pull out the list of vectors, and collapsing the vector with spaces bewteen ones and zeros. I did that, becausetidyr‘sseparatefunction does not let me split up the character string by no spaces. - I still have a list of vectors. Hence, I am converting the list of character vectors into one long vector of strings with
purrr‘sflatten_chrfunction. - Now, I finally can use the
separatefunction to separate thesource_flagcolumn into five columns.
Next, purrr’s imap Function
Now, we will use purrr‘s imap function to see what combination of data sources are most common.
intermediate_df %>% purrr::imap_dfr(~ifelse(.x == 1, .y, "")) %>% tidyr::unite(., col = comb, sep = "_", remove = FALSE) %>% dplyr::mutate(comb = stringr::str_replace_all(comb, "^[^a-z]*", "")) %>% dplyr::mutate(comb = stringr::str_replace_all(comb, "[^[a-z]]+$", "")) %>% dplyr::mutate(comb = stringr::str_replace_all(comb, "(_)\\1+", "\\1")) -> final_df head(final_df) # # A tibble: 6 x 6 # comb tax immigration healthcare credit education # <chr> <chr> <chr> <chr> <chr> <chr> # 1 immigration_credit_educati~ "" immigration "" credit education # 2 immigration_healthcare_cre~ "" immigration healthcare credit "" # 3 tax_healthcare_credit tax "" healthcare credit "" # 4 tax_education tax "" "" "" education # 5 tax_immigration_healthcare~ tax immigration healthcare credit education # 6 tax_immigration_healthcare tax immigration healthcare "" ""
Code explanation:
- I am using the
imapfunction to replace all ones with the column name where the one occurs and leave it blank if a zero occurs. - Next, I am combining (uniting) all columns with an underscore (_) as separator.
- Lastly, some regular expressions for data cleaning purposes.
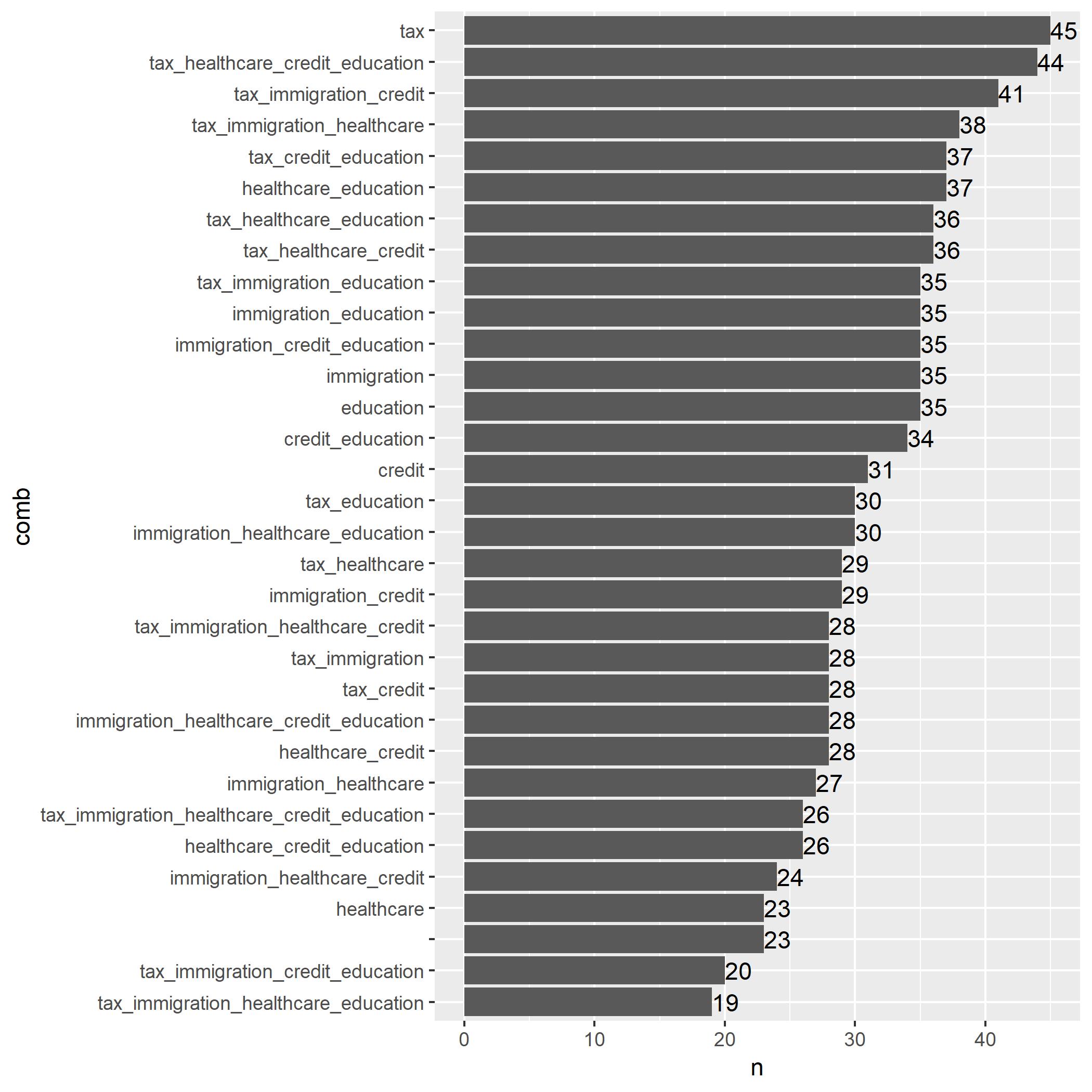
Visualization of Results
final_df %>% dplyr::group_by(comb) %>% dplyr::summarise(n = n()) %>% dplyr::arrange(n) %>% dplyr::mutate(comb = factor(comb, levels = unique(comb))) %>% ggplot(., aes(x = comb, y = n)) + geom_bar(stat = "identity") + coord_flip() + geom_text(aes(label = n), hjust = 0.0)